Anomaly detection algorithms look at an unlabeled dataset of normal events
It learns to detect or raise a red flag for if there is an unusual or an anomalous event
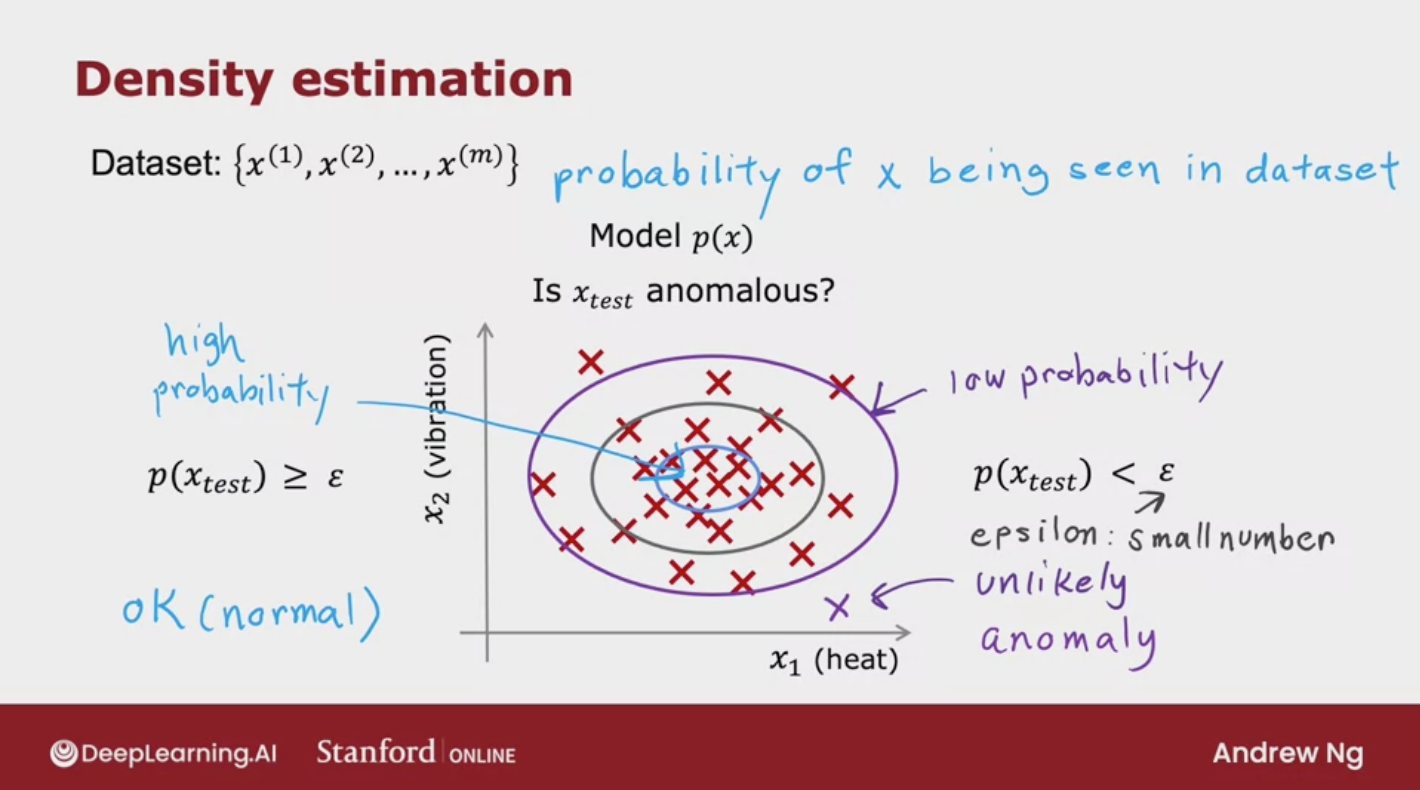
Density estimation
The first thing you do is build a model for the probability of x
The learning algorithm will try to figure out what are the values of the features x1 and x2 that have high probability and what are the values that are less likely or have a lower change or lower probability of being seen in the data set.
Example
Fraud detection
x(i) = feature of user i’s activities
how often login? how may webpages visited? transactions?
Model p(x) from data
Identify unusual users by checking which have p(x)<ϵ
Manufacturing
x(i) = feature of product i
airplane engine, circuitboard, smartphone
Monitoring computers in a data center
x(i) = feature of machine i
x1 memory use, x2 number of disc accesses/sec, etc.
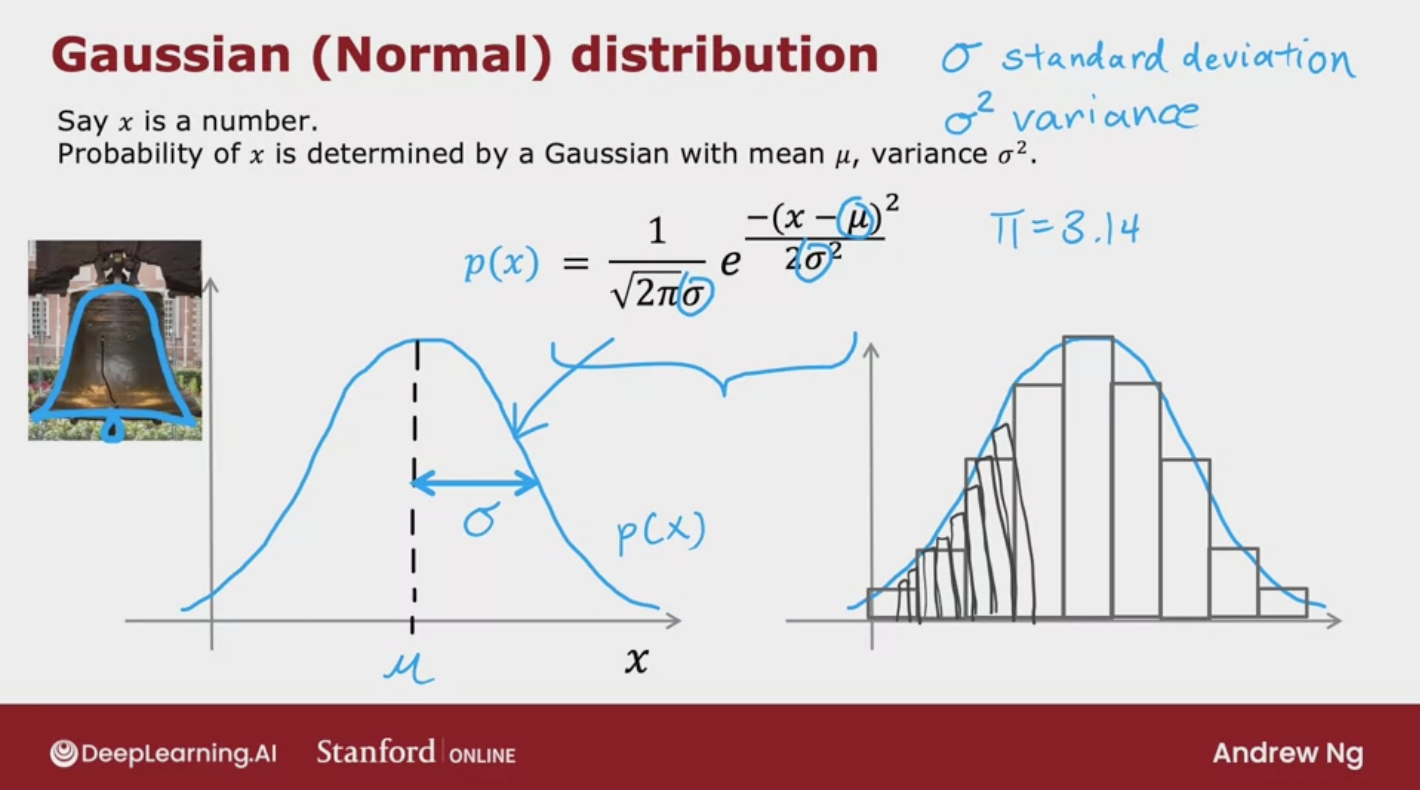
Gaussian (normal) distribution
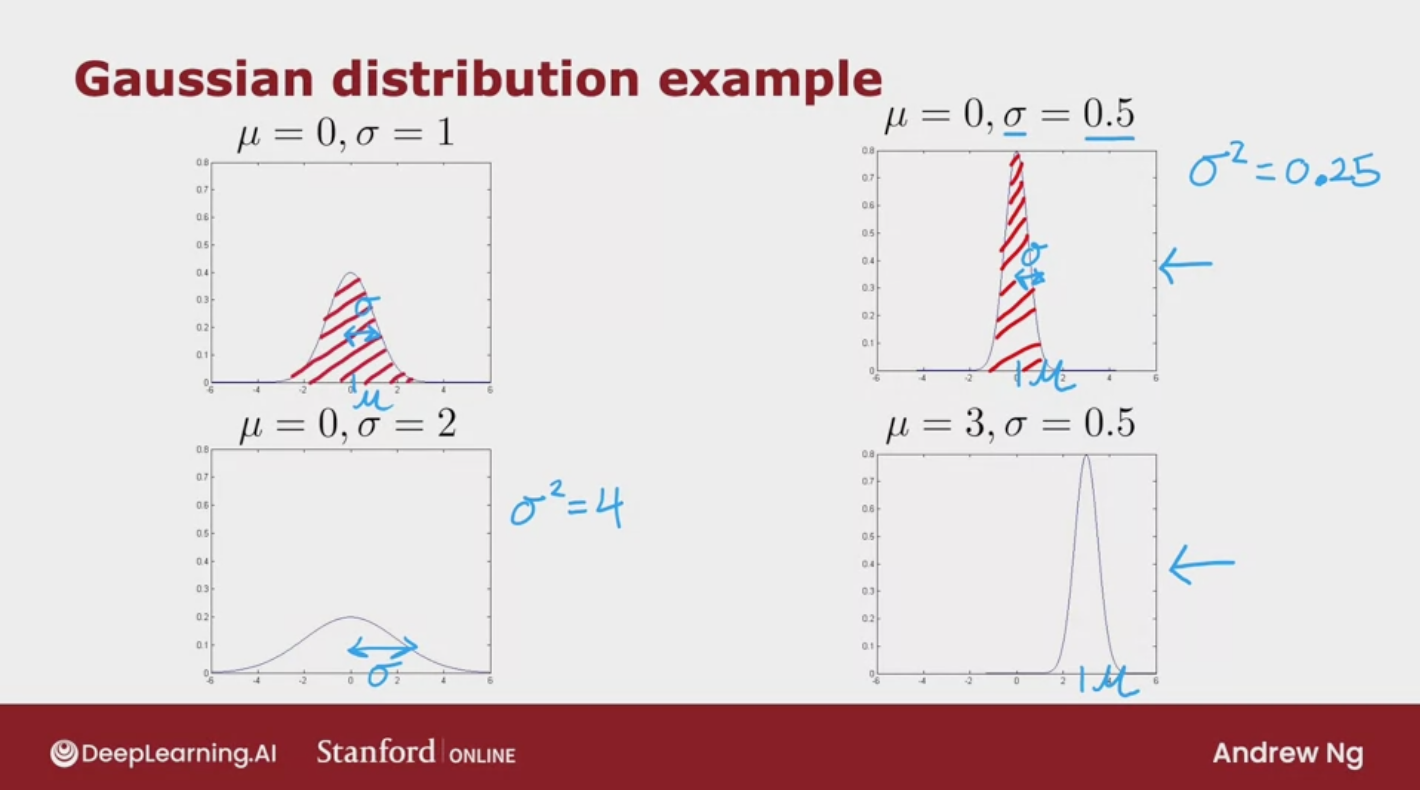
Gaussian distribution example
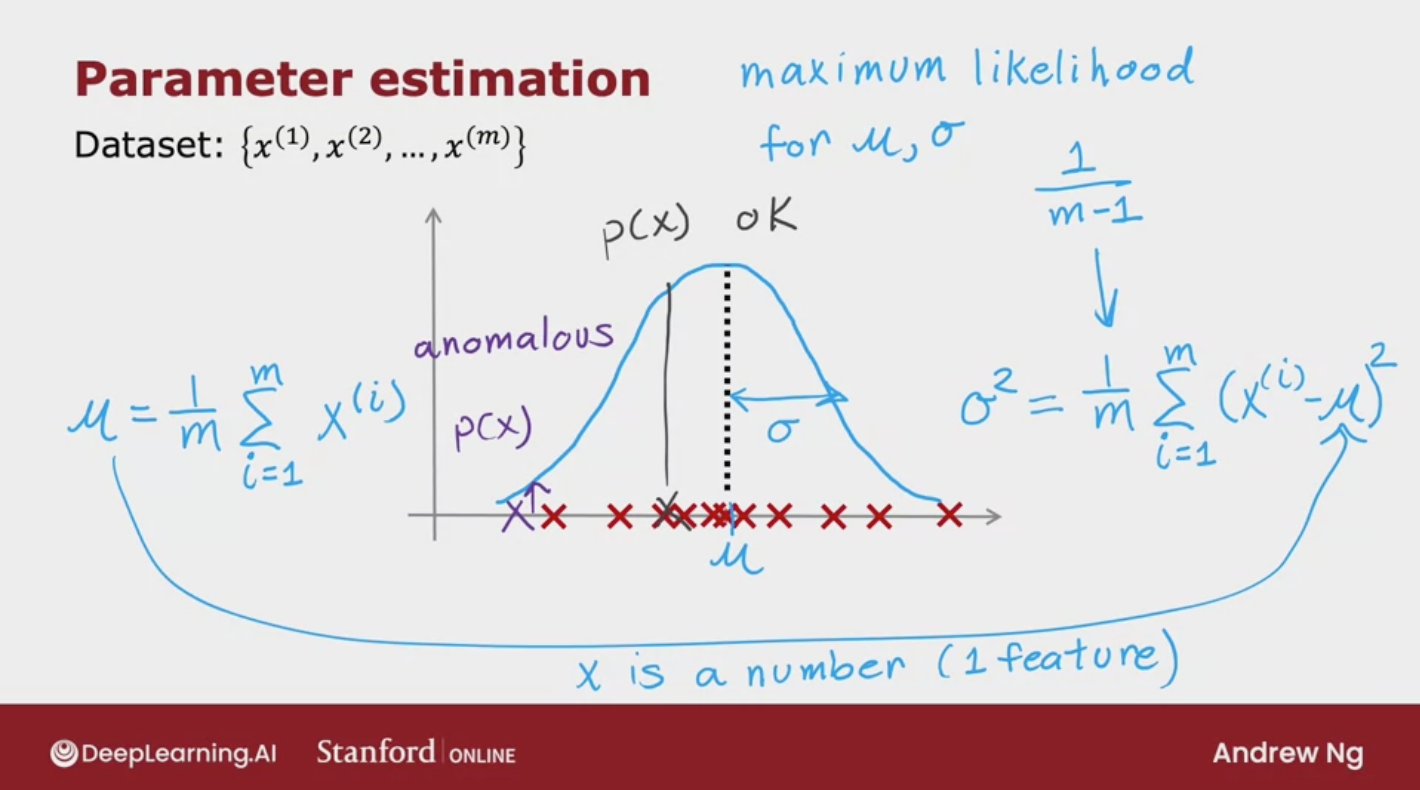
Parameter estimation
Anomaly detection algorithm
Choose n features x1 that you think might be indicative of anomalous examples
Fit parameters μ1,…,μn,ϵ12,…,ϵn2
Given new example x, compute p(x)
Developing and evaluation an anomaly detection system
when developing a learning algorithm (choosing features, etc.), making decision is much easier if we have a way of evaluating our learning algorithm
Anomaly detection vs. supervised learning
Anomaly detection
Very small number of positive examples. Large number of negative examples.
Many different types of anomalies. hard for any algorithm to learn from positive examples what the anomalies look like
future anomalies any look nothing like any of the anomalous example we’ve seen so far
EX) Fraud detection, find new previously unseen defects
Supervised learning
Large number of positive and negative examples
Enough positive examples for algorithm to get a sense of what positive examples are like
future positive examples likely to be similar to ones in training set
EX) Spam email detection, finding known previously seen defects